
Announcement
Jan 28, 2026
Voice AI's DeepSeek moment - Voiceletter #1
Remember when DeepSeek R1 landed, and suddenly the gap between open-source and proprietary reasoning models just collapsed overnight?
Alibaba has done the same thing for TTS.
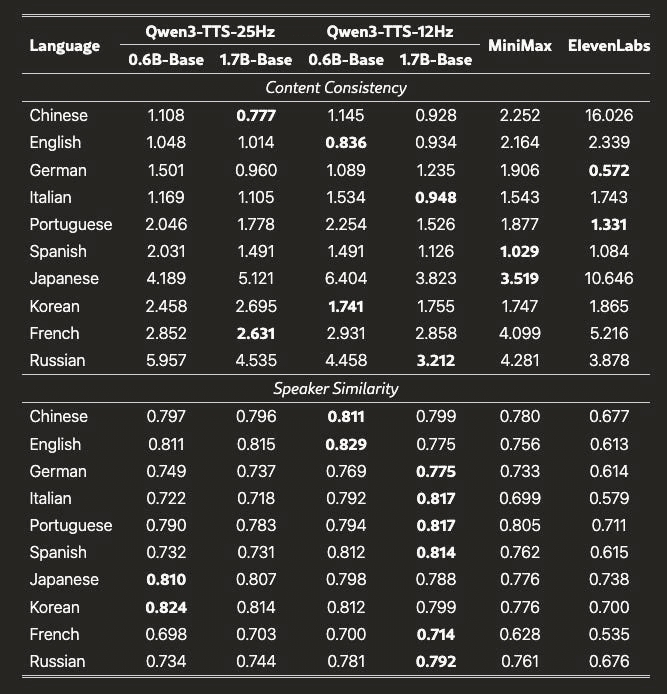
Qwen3-TTS has just been made fully open-source under Apache 2.0.
And I mean fully open-source - not some limited research preview or a demo to get people excited. It’s production-ready models that you can run on your own infrastructure, fine-tune for your exact use case, and deploy without being charged through the API.
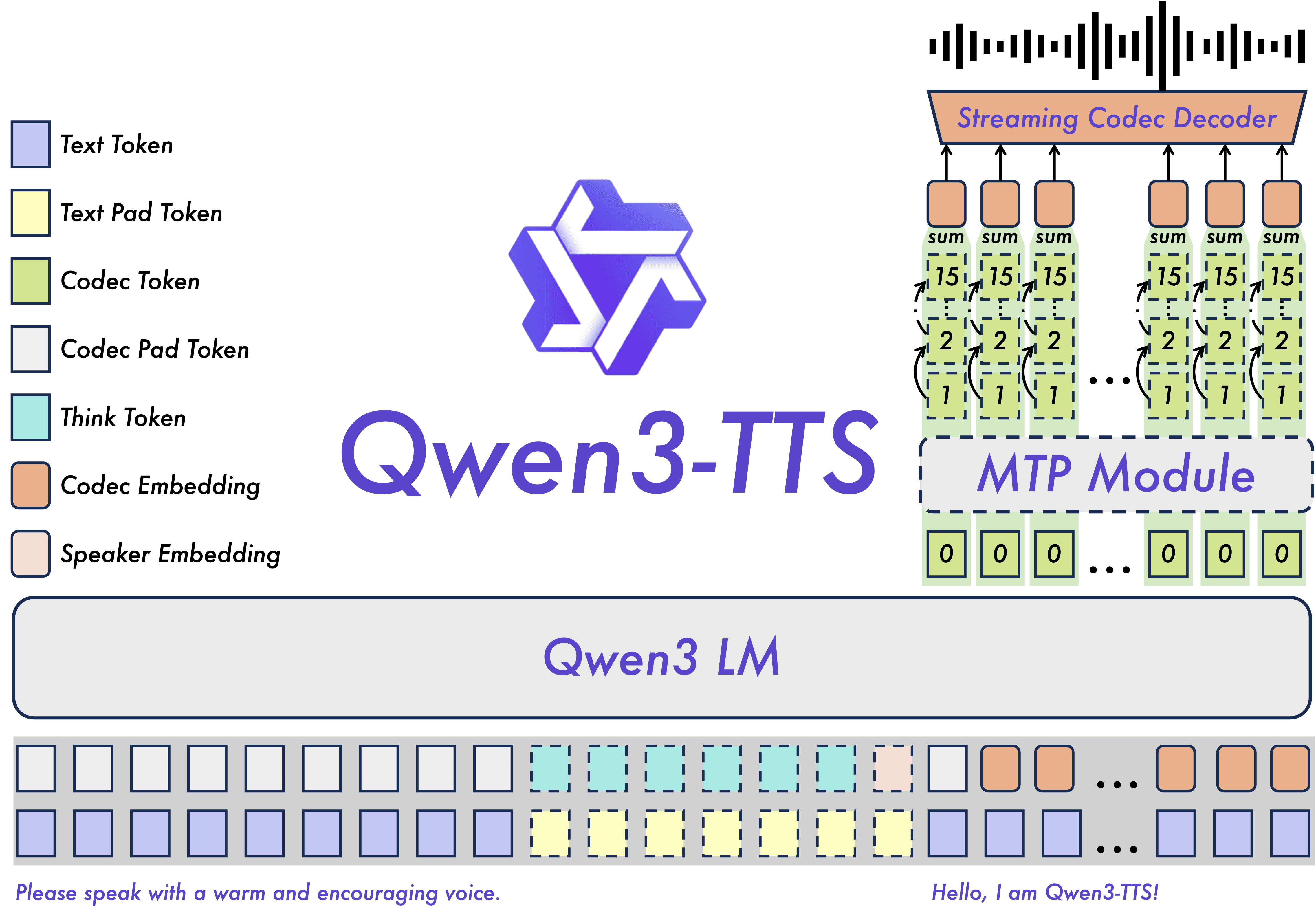
Here’s what Qwen3-TTS is all about:
0.6B and 1.7B parameter models
10 languages
Cloning a voice in 3 seconds using a reference audio clip
Designing a voice using natural language - “gruff pirate voice”, “warm customer service rep” - you get the idea
97ms first-packet latency in streaming mode
And here’s what the benchmarks look like: bwoooy then went bold, comparing directly with ElevenLabs! This isn’t some “good enough for demos” open-source model - it’s competitive with the best proprietary options out there.
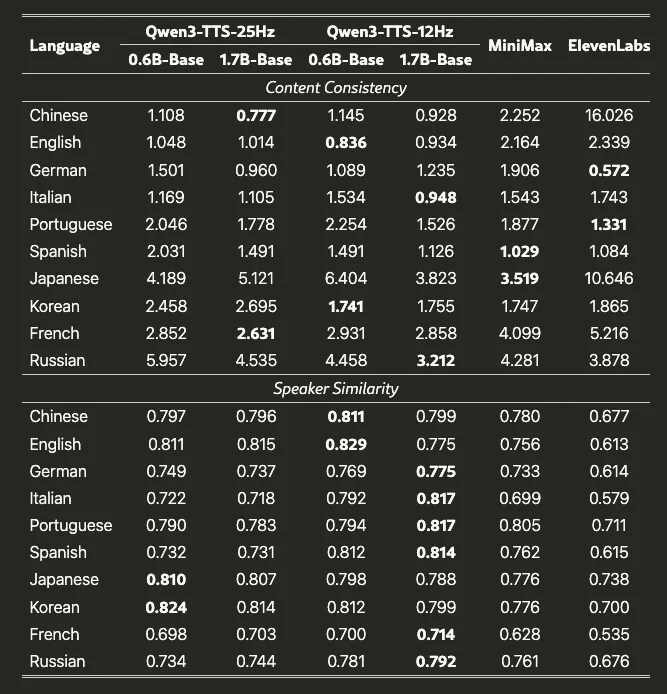
So why is this a big deal for builders:
Until this week, you’re stuck with ElevenLabs, or Cartesia.
And of course, the pricing scales linearly with usage.
Qwen3-TTS breaks that model. If you’ve got high-volume voice agents - contact centers, IVR systems, content generation - the economics shift dramatically when TTS becomes a fixed infrastructure cost instead of a variable API cost.
The question on everyone’s mind is: Can Alibaba do to TTS what DeepSeek did to reasoning? If the quality holds up in production (I’m testing this week and will report back), we might be looking at a fundamental repricing event for the entire TTS market.
Want to play with it? Here’s a demo on HuggingFace
Quick Hits
LiveKit hits unicorn status - $100M Series C at a $1B valuation, led by Index Ventures. LiveKit powers ChatGPT’s Voice Mode, Grok’s voice interface and is used by the likes of Salesforce and Tesla. Now here’s the interesting part - they’re not a voice AI company, they provide infrastructure. This tells you where the smart money thinks value will accrue in this space. When the company powering OpenAI’s voice features raises at $1B, you know the picks-and-shovels play is real.
Deepgram raises $130M- STT market consolidation continues. Deepgram hit a $1.3B valuation and immediately acquired OfOne - a YC startup building voice AI for quick-service restaurants. The vertical play is interesting - Deepgram’s CEO says restaurant ordering might just be the first positive interaction more than 300 million Americans have with voice AI. For builders out there - the big three (Deepgram, AssemblyAI, cloud providers) are consolidating - the smaller STT providers are getting squeezed. TechCrunch
From my experience, I can only imagine that Flux solid release contributed to the valuation - you need to test it!
Pipecat Cloud goes live - Daily launched enterprise hosting for Pipecat, the open-source voice AI orchestration framework. Now here’s why it matters: Pipecat as the dominant open-source framework for building voice agents, now has managed deployment paths, which means you can build on open-source without running your own infrastructure. The vendor lock-in escape hatch is real.
The Infrastructure Thesis
Here’s what connects LiveKit’s unicorn round and Pipecat Cloud’s launch: the infrastructure layer for voice AI is being built outside the big labs.
And I think that’s great news for builders.
When your orchestration framework and your real-time transport are open-source with managed deployment options, you get the best of both worlds - no vendor lock-in on the core architecture, but you don’t have to run it all by yourself.
Now compare that to building on a vertically integrated platform where the orchestration, transport, STT, LLM, and TTS are all bundled. Easier to get started, but you’re locked in at every layer.
In January’s funding rounds, it’s looking like investors are seeing the writing on the wall - infrastructure that works across multiple voice stacks is hands down more valuable than something tied to a single provider.
I’m personally bullish on this direction. OWN YOUR IP. OWN YOUR EVALS.
Quick Take: Voice AI Evals Are Finally Getting Real
Speaking of evals, two things dropped in January that are a big deal for voice AI: it looks like they’re finally maturing.
On ODSC’s podcast Brooke Hopkins (Coval CEO) made a comparison to self-driving car reliability - the same kinds of stochastic systems, the same need to test for every possible scenario, and the same headaches when it comes to catching edge cases before you’re in production. She knows what she’s talking about with that comparison - being at Waymo, she’s seen things :)
Her take on it is simple: you simply can’t manually QA probabilistic systems - you need automated testing on a massive scale.
Builder’s insight - what to simulate for Voice AI? Accents, languages, background noise, interruptions, and workflow variability!
Hamming put out their full Voice AI Evaluation Framework that they developed after analyzing 1 million+ real-life calls. What’s stuck with me is this - they call it the “metric mirage” : the idea that dashboards full of healthy metrics can mask the fact that agents are still messing up.
As Sumanyu (CEO) put it:
“An agent can say the perfect thing and still lose the user because it:
• talks over them
• pauses too long
• misses interruptions/turn-taking
• gets end-of-speech wrong (VAD) and cuts them off”
Their framework is a lot more nuanced - it breaks quality down into Infrastructure → Agent Execution → User Reaction → Business Outcome.
And the thing is - an error at any of those layers can bring the whole thing crashing down.
For all the builders out there who know how crucial evals are for getting voice AI into production, the tooling is finally catching up.
One Thing to Watch For
Coval just dropped their 2026 Voice AI Report (and it’s gated, so you’ll need to give them your email to access it). If it’s got some solid data in there, I’ll do a dive into it in a future edition. The eval companies are seeing more production voice AI than almost anyone else, so their insights tend to be worth paying attention to.
Sign Off
And let’s be real, January isn’t even over yet, and we’ve had more movement than most of Q4 last year. The infrastructure side is consolidating around open-source, the model layer is getting commoditised, and the evals problem is finally getting the serious tooling it needs.
If you’re building voice AI right now, the stack decisions you make over the next few months are going to have a serious multiplier effect. Make ‘em count.
So what’s your TTS setup looking like at the moment? Reply and let me know if you’re planning on giving Qwen3-TTS a spin.
Artur
Blog